|
Continued from - Part 1 Previously published October, 21 2015 There are currently ten top contenders for the most important technologies leading businesses are using to provide a competitive edge. All of these evolved from the need to creatively solve the significant issues faced by small teams trying to quickly deliver great products. Summarized simply as: "How do we build and deliver a product customers love and are willing to pay for as quickly as possible?" 1) Lean startup The traditional route to starting a business is to have a good idea, write a business plan, use the plan to acquire funding, and then implement the plan. Sounds simple, but in practice, things rarely go according to plan. The number one failure point is that your great idea isn't something that enough people will buy to sustain your business model. The answer is simple, focus on finding a customer who will buy the simplest version of the product you can possibly make and then iteratively develop as quickly as possible. The core of this idea was first defined by Steve Blank simply described in the seminal Harvard Business Review article, Why the Lean Start-Up Changes Everything. One of the critical differences is that while existing companies execute a business model, start-ups look for one. - Steve Blank The basis of this model is the continual testing of the business ideas through a process he refers to as Customer Development in which the entire founding team is directly engaged with potential customers to discover the combination of product, price, and delivery model customers are willing to buy. 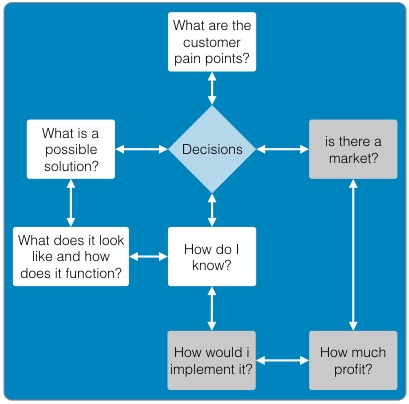 There have been a number of tools developed to assist in the process and while these may look like the sections in a traditional business plan, the way they are executed is dramatically different and reflects the collaborative underpinnings of all the other technologies. This is a truly iterative and interactive process. Typically, the various canvases and worksheets [1] are printed out, hung on a wall and completed by the entire team as they gain feedback from potential customers. As the team continuously makes decisions, they ripple through each of the canvasses until a coherent business model is arrived at. 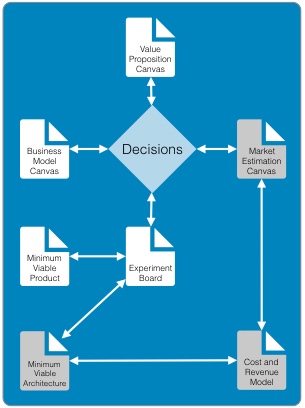 The MVP In some cases, the creation of an actual sellable product may be delayed as multiple low fidelity versions are tried out. An example might be an iPhone application produced entirely in Keynote, an Arduino driven hardware prototype, or a more finished sellable prototype [2]. These low fidelity products are referred to as Minimum Viable Products (MVP) because they represent an experiment to learn something about what a customer needs or wants, not necessarily a complete product. This concept of continuous experimentation and focus on delivering small units of targeted functionality is a core driving concept in these ten key technologies. What is the best way to size the MVPs? Stick with orders of magnitude. Build a product for your first paying customer, then ten customers, then your first hundred, nothing more. In practice, you want to build for two orders of magnitude (e.g., 1-10 customers, then 100-1000). Unfortunately, this important rule of thumb hides a nasty truth. The product you build for your tenth customer will be significantly different from the one you built for the thousandth. If it is software, understand this means a complete rewrite. If it is hardware, it will require significant process and or tooling changes. In both cases, it is effectively a complete redesign. The obvious solution is to build in extra capacity, be it process automation, bigger servers, or better software. However, this frequently leads to a situation where it is more difficult to quickly modify the product to meet not only the scaling needs but the inevitable feature changes. Alternatively, build products that are easy to modularize or dispose of from the start. 2) Micro services Micro services, Web Services, and Service Oriented Architectures (SOA) are ways of addressing the modularity problem. On the surface, it is easy to confuse these technology patterns because of their panacea status at various times over the last two decades. A service-oriented architecture is a style of multi-tier computing that helps organizations share logic and data among multiple applications and usage modes. -Gardner, 1996 [3] The basic idea is this: Clearly define a specific business domain [4] and expose needed data in a way that is easy for other systems to consume. The different flavors simply reflect interface details and vendor marketing. By and large, SOA and Web Services have been coopted by software vendors to sell an entire class of software called Middleware. In a large company, you typically find suites of vendor specific applications designed to integrate well with each other but little to no capability to integrate with systems from other companies. Hence, the need for large and complex middleware. Middleware comes in many flavors. Generally, it can be grouped into three classes. Enterprise Information Integration (EII) promises to make all of your data seamlessly available, in realtime, regardless of original format. Enterprise Application Integration (EAI) promises to weave data together with complex business logic in a way that applications can subscribe to just the data they need. Not to be left out, Extract, Transform, and Load (ETL) is frequently added to the mix to address the issue of bulk data transfer. Collectively, these are referred to as an Enterprise Service Bus (ESB). As you can guess from their names, the intended audience for these applications are large enterprises with complex systems. 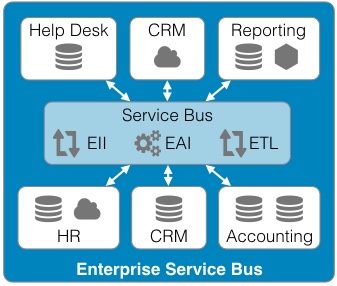 There are many problems with this middleware integration model. First it is costly and complex, not; typically requiring a separate Integration Services Organization just to manage the infrastructure, service definitions, and development. This centralization requires project requests to be prioritized and driven by external organizations resulting in unnecessarily extended delivery timelines. Secondly, this centralization reduces the resiliency of the system in such a way that any outage or a reduction in service of the Service Bus can inadvertently affect every system in the company. Finally, a centralized and single vendor service bus makes it nearly impossible to change vendors or make large scale infrastructure changes possible. Taken together, the Enterprise Service Bus exposes a company to significant competitive risks that far outweigh any benefits. Micro services are a better answer because they offer faster delivery, developer independence, system resiliency, and potentially lower costs. What is a micro service (microservice / micro-service)? Simply put, it is a way of creating applications which are purposeful, small, flexible, composable, and compostable. Think of micro services as big iPhone apps that are built to scale, be shared, and be swapped out as needed. Martin Fowler has a longer more technically accurate definition: In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often a HTTP. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies. [5] Traditionally, big applications (and even smaller ones) are built to be self contained and deliver broad functionality. They typically have a user interface, an application tier, and a database tier. If they integrate with other systems, it is either within a suite from the same vendor (e.g., SAP) or unofficially through an ESB or direct database connections. These applications can be referred to as *Monoliths*. From a deployment perspective, the monolithic application is typically treated as a single entity and very seldom does an upgrade to the application not affect the database and user interface. In smaller applications, this is not a problem but as applications and organizations scale, this becomes a significant constraint on the ability to deliver changes quickly. 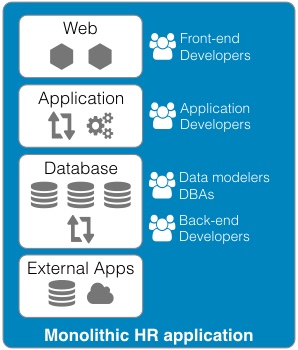 Managing monolithic applications in large companies is further complicated by the fact that the support and development teams are grouped by the tiers of the application. In the most dramatic example, entire development teams may support multiple, unrelated applications. This was previously mentioned in the ESB example but also applies to Business Intelligence and Infrastructure functions as well. The default organizational response to complexity and size is to group people by jobs and then split applications up by those same jobs. Shared applications become Common Services and even within application teams, you have such things as front-end and back-end developers. This organizational structure is not necessarily a problem but it can significantly impair flexibility and delivery. This propensity is referred to as Conway's Law [6] Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure. - Mel Conway Breaking the Monolith What then is an alternative structure? Align developers to customers and have them focus on delivering purposeful, small, flexible, composable, and compostable applications. One team, One service, Total responsibility. 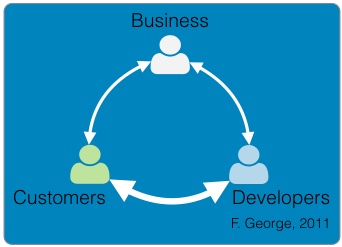 Small team size is the key. Small teams are better able to communicate with the customer and each other. The increased communication directly translates into agility to respond to changes; it also instills ownership in the end product. The catch is that small teams may be limited in the complexity of product they can produce. However, in an organization developing micro services, this is an advantage. Consider the situation where a company wants to migrate from a dedicated local HR Application to a hosted HR suite. It is highly likely that there will be missing functionality in the new application and as a result, hard cut-over will be impossible. How can this be addressed? First, look at the required functionality. Perhaps the new application doesn't offer time recording as a feature. Acknowledgement of this fact and the prioritization of Attendance as an important business service should be easy. Second, dedicate a small team to the problem and have them focus on creating the best Attendance system they can, as quickly as possible. "If you can't feed a team with two pizzas, it's too large" - Jeff Bezos [7] This team has complete ownership for the solution and the authority to work with any and all customers they identify as key. Most importantly, they own this service going forward. Whether they choose to utilize another hosted service or write their own is their decision. [8] 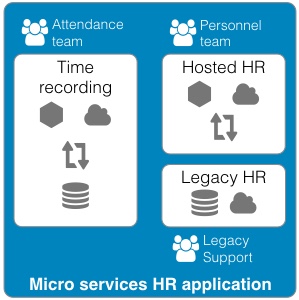 One of the key attributes of the micro services architecture is that every service be composable. This means that a service exposes key functionality to other services in a way that is stable, well documented, and easy to interface with. This legibility makes it possible to leverage the functionality in other services in a consistent manner. This ease of use means that it is simple to build up new services. For instance, it may now be trivial for a team to build a "Find a back-up service" by integrating multiple services into something completely new. 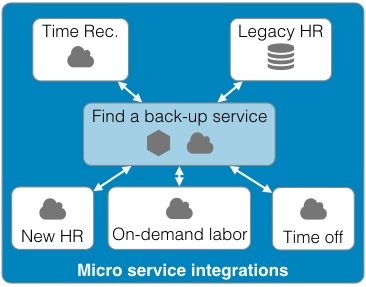 The final attribute, compostability, refers to the fact that these small, discrete services are under constant revision and when they are no longer needed, they are shut down entirely. It also refers to the ability to dynamically scale to meet consumer demand, increasing and decreasing the number of nodes as needed. Unfortunately, micro services are not the answer to every problem. The added complexity is definitely not appropriate for the initial versions of a product. Typically, it is much easier to build initial versions as monoliths. It is hard to imagine that Amazon started out this way. Amazon.com started 10 years ago as a monolithic application, running on a Web server, talking to a database on the back end. This application, dubbed Obidos, evolved to hold all the business logic, all the display logic, and all the functionality that Amazon eventually became famous for: similarities, recommendations, Listmania, reviews, etc. ... This went on until 2001 when it became clear that the front-end application couldn’t scale anymore. [9] However, there are key design decisions that can comfortably be made in early versions which can make breaking up the monolith much easier in the future. Fortunately, the remaining eight technologies all provide this level of flexibility. [10] 3) DevOps ... Giving developers operational responsibilities has greatly enhanced the quality of the services, both from a customer and a technology point of view. The traditional model is that you take your software to the wall that separates development and operations, and throw it over and then forget about it. Not at Amazon. You build it, you run it. This brings developers into contact with the day-to-day operation of their software. It also brings them into day-to-day contact with the customer. This customer feedback loop is essential for improving the quality of the service. [9] This is the key motivation behind the DevOps movement. In practice though it isn't enough to tell a development team that they are free to build the best service, using any tool they want, and that support is up to them. Successful implementation of a Continuous Deployment pipeline requires a large number of integrated tools and processes to be successful. Furthermore, these systems must be as automated as possible. If successfully implemented, the cycle time for a release can be brought down from months, as is typical in monolithic corporate systems, to hours or less. [11] Common Services definitely have a place in a DevOps environment. However, they should supply not only the core server, networking, security, and management infrastructure, but the tooling to support the Continuous Build and Integration processes. The list of these required additional services is overwhelming but the DevOps centric development frameworks typically pre-integrate with a number of the more common support tools such as GitHub for the Code Repository or AWS AMI or Docker Hub for the Image Repository. The more mature frameworks have easy to use Build, Integration, and Testing pipelines as well. [12] 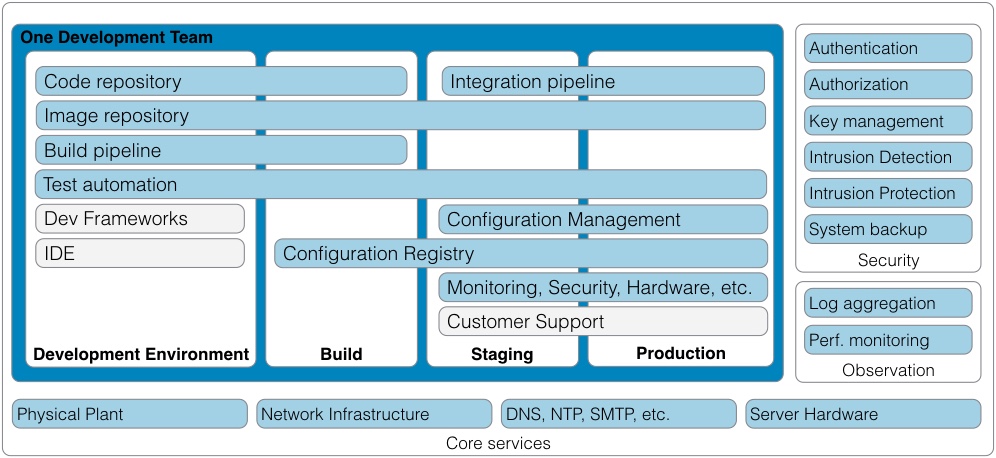 One word of caution. If you are in the experimentation phase, many of these integration tasks can and should be done manually. The goal is to improve the product to the point where you will need the underlying automation. Until then, you don't need to solve these problems. Fortunately, most of the more common supporting applications scale up well and support a high degree of interoperability. As a result, changing a monitoring and logging framework at a later date may have little impact on an application. "You don't have that problem yet." - Anonymous Creating a DevOps environment from scratch is a daunting task requiring many people with a wide ranging set of skills, and a significant investment. Fortunately, at early stages of a product, particularly with monolithic early versions, developers can easily handle these tasks given the right development strategy and tools. 4) Full Stack development When we looked at the monolithic HR application previously, it was noted that the various tiers of the application were supported by different development organizations. One of the drivers for this differentiation is the fact that each tier of the application is written in a different and unrelated language. While it is possible that a senior developer may be fluent in more than one language it is unlikely that a junior will be. 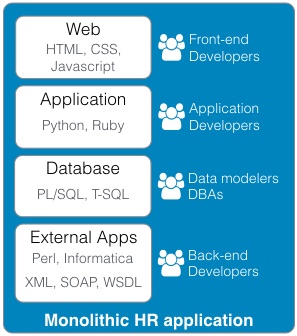 This presents two issues. One, this specialization severely limits the ability of a developer to assist another group in the event they are understaffed. More importantly, it limits the ability of a developer to understand the full scope and intention of the application. In the event the application must integrate with other services (e.g., reporting), it may be extremely difficult understand the logic between the database and the web interface. There is a better solution to this issue. Due to advances in the Javascript language, most notably Node.js, it is now possible to write an entire application in one language, Javascript. When this is coupled with a database that provides a native Javascript interface, any developer can now participate in the delivery of new features within any portion of the application, at any time, with minimal disruption to the team. The benefit of this cannot be over emphasized. Having one central language means that you have one unified development team who can truly and easily take full responsibility for the application they have built. Having a unified development stack means that support is also greatly simplified as well. Node applications are inherently scalable and most Full Stack frameworks like AngularJS, Ember, Hapi, and Meteor support the development of functional MVP web applications up to world class consumer e-commerce sites. [13] There is even a framework for building cross platform desktop applications (nwjs.io) and for converting these applications to native mobile apps (PhoneGap). 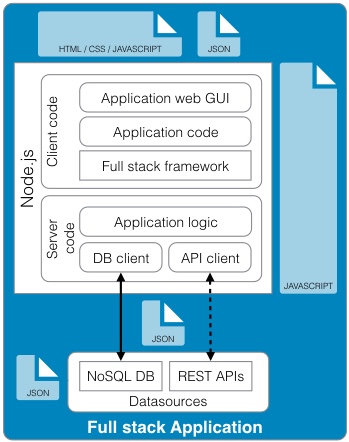 Under the covers, the web interface is traditional HTML, CSS, and Javascript. The data being exchanged with the server is in the standard Javascript Object Notation (JSON) format . On the server side, all code is written in Javascript. This provides an interesting advantage for a developer. It is not only possible, but it is a best practice to reuse server side code on the client and vice versa. Consider validation. It is now possible to write one validation function and execute it on the client to pre-validate form input, then use the same code to validate the data before it is written to the server, and then again when the data is read from the server and sent to the user's browser or to another application through an Application Programming Interface (API). If you are used to traditional web applications, you might be wondering where the web server is. In a Node based application, Node is the web server. Part of your application will include writing the server, yet another simplification to speed development and improve supportability.  Some of the frameworks, notably hapi.js, even support advanced web server features like proxying to allow you to seamlessly redirect traffic. This can be useful to redirect legacy web traffic to a new application. This technique is critical to being able to successfully break up monolithic applications. Another traditional web server feature built into hapi.js is caching. This allows a developer to easily manage complex caching behavior directly within the application without having to manage the configuration on an external web server, this greatly simplifies the application architecture. [14] 5) Reactive applications Web applications have always been slower than native applications. Think Microsoft Word running on your laptop versus Word running in a web browser. Reactive web applications are not only an answer to the issue of latency but also a way to provide applications with real time interactivity. In a Full Stack framework, the web application is typically a Single Page Web Application (SPA). This means that the entire web GUI is sent to the user's web page only once and it contains all of the application and presentation logic. Because all of the application code is in the users web browser, and there are no browser requests back to the server for new web pages, any changes to the interface occur instantaneously. That is assuming no new data needs to be sent to and from the server. Solving the latency for data transfers has been a significant area of development recently and has led to the creation of Reactive Web Frameworks and Reactive Databases. [15] 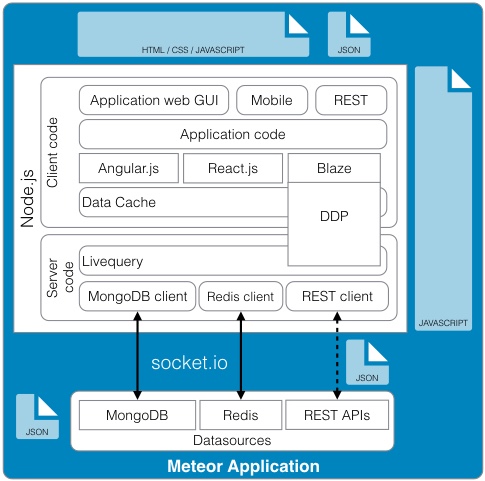 In a Single Page Application, application latency is largely attributable to the transfer of data. One method of solving this in the past has been to use Asynchronous Javascript and XML (AJAX) to progressively retrieve data from the web application server. Reactive web frameworks like Meteor extend this approach by implementing a client side data cache. In effect, there is a mini version the noSQL database back end running in the web browser. When a user sends a request to the database, it is first written to the mini database and the client interface is instantly updated. In the background, the client code updates the database and if the results happen to be different, the webpage is re-updated. To the user, all of this is invisible and instantaneous, even if there is a significant delay in the back-end application. Similar to the validation example, the code used to interface with the in-browser database and the actual database is identical. No need to implement a cache with a different API. From a client perspective, database updates appear nearly instantaneous because of this local data cache. On the server side, Meteor leverages the Socket.IO package to create a real-time connection to the database so that it appears that any changes on the database are automatically pushed to the client and the web page is automatically updated without having to refresh the page. This means that it is possible to create multi-user applications which automatically reflect the real-time status of all of the other users of the application. Furthermore, Meteor supports a feature they call Hot Code Push. Hot Code Push allows a developer to push code changes to production and Meteor will seamlessly update the client code on all connected application users. This ensures that every user instantly has the most recent version of the application running on their browser or iPhone. Meteor's reactive extensions to MongoDB and Redis provide a quasi-realtime interface between the database and the application. RethinkDB provides a native realtime interface by bi-directionally streaming data between the application and database. This allows developers using other web frameworks supporting Socket.IO to also build true realtime applications. 6) Keys, values, and JSON As previously mentioned, in the past, web applications exchanged data with other systems using a variety of formats. Applications and browsers exchanged URLs and HTML. Applications and databases communicated through native database software, and if an application exchanged data with another system the data format could be plain text, raw XML, SOAP XML, or JSON. Modern web frameworks have settled the debate. The default data interchange format is now JSON. [16] The trick to understanding JSON is to understand Key : Value pairs. A Key : Value pair is a way of describing a thing (e.g., name) and an attribute of that thing (e.g., Bob). This can be written as "name" : "Bob". In Javascript, this is called an Object, hence the name Javascript Object Notation or JSON. The Javascript specification extends this simple structure to support arrays, which are groupings of things like "color": ["red","blue", "green"].  These two primitives can be combined in a multitude of ways to describe many types of complex relationships and because they are native Javascript structures, it is easy to query, read, and manipulate them. An added advantage is that a JSON object represents a complete aggregation of the data for that object. This can include complex nesting of objects. No need to join multiple sets of data together or ensure that every object attribute is present. In this way JSON is a more natural way to model something. As a result, it is typically much faster to model data in JSON format.  7) Document databases While there have always been many different types of databases (e.g., Relational, Object, XML, etc.) the relational database has been the dominant type for at least the last thirty years. The key concept of a relational database is that it takes a complex issue like how many phone numbers a person has and decomposes this data into separate tables in the interest of saving space. This process is called normalization and it minimizes the redundancy of data within the database which makes the database smaller. 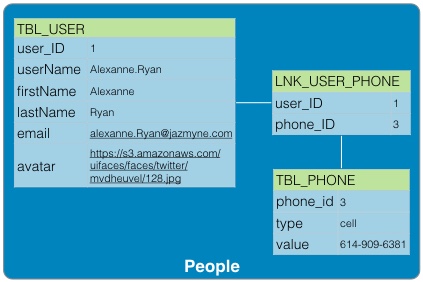 The primary advantage of Relational Database Management Systems (RDBMS) is that they are typically very fast and ensure a single point of truth for the data at any point in time. However, having a very efficient complex but complex data model makes it difficult for a developer to consume the data because they need to understand how many different but related tables need to be combined together in a query. In order to relieve this problem, it is common practice to recombine the data into easy to consume views (denormalization) in order to simplify the use of the data.  Relational databases also require a database application. This seems obvious but it is not actually a given. Javascript based applications can be, and frequently are written with the JSON object (the database) simply embedded in the Javascript as a variable or written to a file. As a result, when it comes time to migrate to an actual database, few changes are required in the application. While it is possible to mock up data from a relational database as a flat file for an application, moving to the actual database requires a significant refactoring of the data. This becomes even more difficult if the data is to be written to multiple tables. Document databases are a response to this complication. Document databases store their data in JSON format, return data to applications in JSON format, and typically are queried using JSON format. As a result, it is very natural for a developer to use a document database. [17] The JSON syntax also offers sufficient flexibility to model most relational data and while the Key: Value structure may have some inefficiencies, it is much more efficient than storing both normalized and denormalized views of the data. Furthermore, because a query against a document does not require joins, document databases are typically much more responsive. [18]  Document databases are still relatively young and there are a number of prominent variations. Together these are referred to as noSQL Databases. noSQL is a hashtag and nothing more. [19] There are many variants of noSQL database structures, all appropriate for specific use cases. Selecting the right one depends on the specific requirements you have. The most popular solution for development at this time is to use MongoDB as the document store and Redis as the caching store. However, there are many other options to choose from, including dedicated proprietary databases from Amazon, Google, and Microsoft. Pure Document databases - These databases store document in some form of JSON structure and typically offer a great deal of flexibility and scalability. They frequently support special indices on specific data types: single, compound, and multi-field indices like in a relational database, full text indeces allowing an application to support freeform search on text fields, and geospatial indices to support proximity based searches. Examples: MongoDB, CouchDB / PouchDB, RethinkDB, Crate.io Key / Value databases - These special purpose databases support a very simple document structure of a single indexed key and an associated value. The value can be any type of data imaginable. This provides a great deal of flexibility when you need data based on one and only one key. These systems are typically used in high volume / low latency situations and the data is generally stored in memory not on disk. Examples: Redis, Memcached, ElephantDB, DynamoDB Columnar databases - These databases are more similar to relational databases and some variants even support joins and SQL. However, because the basic data structure is a single table, they avoid a number of the scaling issues of relational databases. Examples: Cassandra, HBase, Vertica, SimpleDB Graph databases - These databases are designed to store the relationships between objects. These systems typically support special analytics queries like shortest path, nearest neighbor, and clustering. Examples: Neo4j Multi-Modal databases - These are noSQL databases supporting multiple types of documents. They offer a great deal of flexibility, typically supporting Key : Value, Document, and Graph modes within the same database. Examples: ArangoDB, OrientDB As you can see, there are many options within the noSQL database world and each database has its own strengths and weaknesses. The best rule of thumb is to start with the simplest system possible that meets the requirements and nothing more. Only as data volumes and complexity grow, should the focus turn to scalability. 8) Database scalability Improving database scalability requires a number of factors to be balanced and different techniques can be combined to achieve numerous results. Some combinations maximize sheer scale, some maximize availability, some maximize capacity and utilization. There isn't one right way to scale a system and it's an art to balance the needs and constraints of a particular database at any given time. 1. Scale up the hardware - This is the obvious first line of defense but it suffers from the limitation that hardware can only scale to a certain size. Intentionally under provisioning it to meet some future need is an extremely inefficient use of resources. A better solution would be to keep to the order of magnitude rule of thumb and size the system as appropriately as possible but with a 10x capacity buffer. Remember, by the time you need the extra capacity, you will probably need a new architecture. 2. Mirroring with failover (Hot / Cold standby) - Mirroring can help to address the availability issue by providing an alternate system in the event the primary system is offline. This is an expensive alternative, but for smaller databases, it may be acceptable, particularly in virtual environments where there is shared data (e.g., NAS) and no cost to maintain offline system images. 3. Clustering - The next step up in functionality and complexity is to cluster multiple systems together so that they appear as one. There are multiple ways to accomplish this: clustered servers with shared data storage, or clustered servers with dedicated copies of the data. One complication with clustering schemes is that you begin to run into concurrency issues when multiple users write to multiple systems at the same time. The simplest option is to designate a single server to accept writes and all of the other servers are read only. This is referred to as a single master cluster. The more sophisticated option is to accept database writes to any server. This is referred to as a multi master cluster. Obviously, a multi master cluster is superior, but it is also more complex. There are also situations, like reporting, where you would want to maintain tight control over the nodes that can be elected to accept writes. You would never want a read only reporting replica to become the master except in cases of extreme fail over. NOTE: For non-database systems, clustering behind a load balancer is the typical method for simultaneously improving availability and capacity. In parallel with the first three options, the data needs to be carefully analyzed to determine if there are ways to optimize data organization to improve query latency and data scalability. This typically involves grouping or splitting up the data in different ways. 4. Horizontal Partitioning - If the constraint is storage, then aggressively normalizing the data can have significant benefits because the data is no longer being duplicated in multiple tables (e.g., 3rd Normal Form). This leads to a significant increase in the complexity of the tables but paradoxically, it can increase the flexibility of the system because disparate data can now be flexibly linked together to answer a wide variety of business questions not explicitly modeled in the database. Compromises to this in relational systems are possible, with the most popular being the Star Schema wherein the measurable (quantitative) data is placed in the fact tables and the descriptive (qualitative) data is placed into dimension tables. This structure is ideal for reporting purposes but sub-optimal for transactional systems requiring low write latency because of the volume of data in the fact table. 5. Vertical Partitioning - At some point, the data volumes in a table can not be effectively queried or even written to. The last remaining option is to split the data into logical groups and to store some of the data in another location, typically another table but it could also be another server. This is referred to as vertical partitioning. Managing data in another table is not particularity complicated, but when the data is split across multiple server nodes, knowing what server the data is on presents a difficult query problem. In a relational database system, this issue is drastically compounded because you also need to maintain the joins to related tables that may be on multiple nodes. 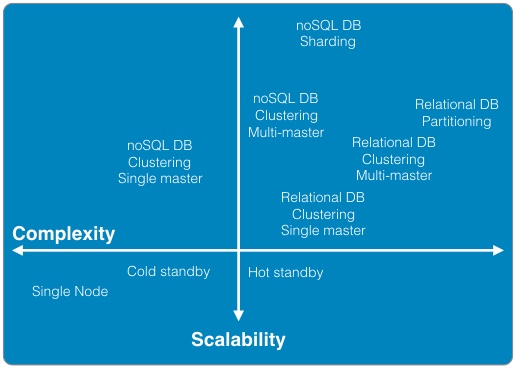 The complexity of maintaining the referential integrity across large volumes of data in a relational database system severely limits the scalability and potential cost of these systems. Taken together, clustering and partitioning are known as horizontal scalability. Fortunately, noSQL databases are built from the ground up with horizontal scalability in mind. noSQL scaling In noSQL systems, the two basic methods of scaling using clustering and partitioning apply. In the most basic form, you replicate data across multiple servers, with each server holding identical copies of the same data. In some systems, you have fine grained control of the replication scheme. Some examples are: allowing for delayed replication in the case that a database change needs to be rolled back, regional replication across continents to provide robust disaster recovery, low latency read only replication, and memory only replicas for extremely low latency caching of data within the cluster. 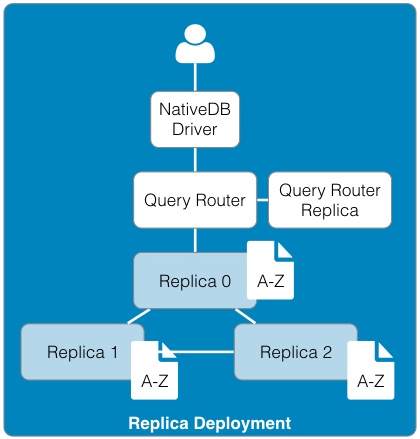 The second clustering option is to horizontally partition the data across multiple cluster nodes. In noSQL systems, this partitioning is trivial because a single document contains all of the data pertinent to that document. There are no data relationships to manage like in a relational database. Because documents are never split across nodes in the cluster, the query router only needs to manage how the collections of documents are split and where they are located. In most cases, it is possible to shard the data in such a way that completely avoids querying multiple servers. This provides both scale and speed. Furthermore, horizontal partitioning is combined with replication to achieve the impossible: a database system that is very large, very fast, highly available, easy to support, and easy to modify. Scale, Speed, Availability, Supportability, and Flexibility. Pick all five. 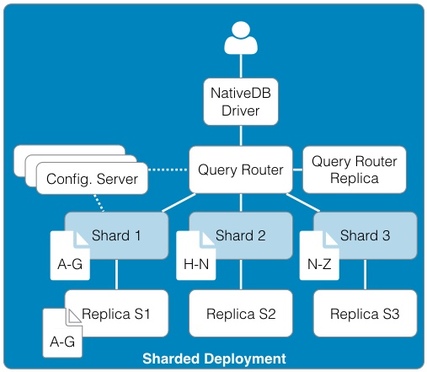 While it seems like noSQL databases are the answer to every data management problem, there are two areas where traditional relational databases still maintain distinct advantages. First, the ability to freely join many tables of data provides a great deal of flexibility when it comes time to answer ad-hoc questions across multiple types of data. The document centric focus of noSQL systems means that if you do not have the data in a document you need, or if it is not structured in the way you need it, you may need to run background processes to create new documents with the form you need. For most noSQL databases, this is provided by a Map / Reduce aggregation batch process. But, if you need to support ad-hoc reporting, relational data warehouses and data marts still have a place. A second issue with noSQL databases is that they typically take an eventual consistency attitude to the replication of data across nodes. This means that the data you write to the database will eventually be written to every node. Unfortunately, it may be possible for a query to return stale data. The tradeoff is speed and scalability with timeliness. Relational systems go to great lengths to avoid this problem and this feature accounts for the cost and complexity differences between these two database architectures. 9) Open Hardware Given the fact that Full Stack web development platforms and noSQL databases are built to scale from one server to thousands, companies have started to critically assess their hardware requirements. If you have data needs requiring large clusters of dedicated servers coupled with application software providing flexible scalability and resilience to failure rather than a reliance on hardware resiliency, you may be able to deploy servers without all of the Enterprise Grade features like Registered Error correcting RAM (ECC RDIMM), redundant power supplies, hot swappable disks, and complex SAN and RAID controllers. The problem was so significant at Facebook that they have championed the idea of building their own custom servers and open sourcing the hardware so that other companies can benefit and improve upon their designs. [20] As a result, server hardware has become completely commoditized and there is little incentive for a company to purchase anything other than Open Compute Project (OCP) compliant hardware in many situations. [21]  What about scaling way down? Open Hardware projects like Raspberry Pi enable the creation of micro-clusters at prices well below traditional servers. These small computers have severely limited capacity but at $40.00 a node, for the price of one Amazon t2.micro instance [22] you could have a three node cluster of Raspberry Pi servers running Node or Docker. What kind of interesting applications could be developed specifically for this platform? [23]  Realistically, you would never use a computer as limited as a Raspberry Pi as a server, but there are situations where it would be beneficial to have dedicated hardware, and a full size server would be too much. An alternative may be to turn to Micro-Servers. Advanced Micro-Servers are designed to provide dedicated hardware within a high density enclosure (e.g., HP Moonshot). This highly proprietary server comes with significant capacity, power, cooling, and networking advantages over traditional servers for certain workloads.  Along with massive integration, these Micro-Servers forego the traditional server CPUs (e.g., Intel Xenon) for very low power CPUs (e.g., Intel Atom based Avaton / Xenon D). The sacrifice in raw computing performance is made up for in power and thermal efficiencies. [24] The price, performance, and power of these CPUs makes them the ideal choice for most workloads and definitely the preferred choice for development and pre-production servers. Fortunately, these CPUs are available in more traditional server chassis and motherboard configurations from most of the commodity motherboard manufacturers. This second class of general Micro-Servers, while not technically OCP compliant, offer a compelling alternative to higher end enterprise class machines from HP, Lenovo, Cisco, and Dell.  10) Containers Hypervisors We have long been at a point in time where servers are more powerful than the applications we can write. This presents a problem. How can we subdivide a server into smaller portions more properly matched to our capacity requirements? The answer is server virtualization. Virtualization offers the ability to locate many *Guest* servers onto a single *Host* server. There are two ways to implement this. In Type 2 virtualization there is a host operating system running virtualization software generically referred to as a Hypervisor. The Hypervisor is responsible for all of the resources (CPU, memory, and disk) assigned to the Virtual Machine (VM). Inside of this Virtual Machine, we have an Operating System and associated applications. 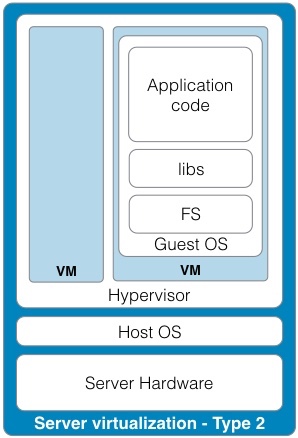 In Type 1 virtualization, the Hypervisor runs directly on the server hardware. In effect it is a specialized operating system designed to manage Virtual Machines (VM). The advantage of this type of virtualization is that it provides more resources to the VM and hence, greater server density. 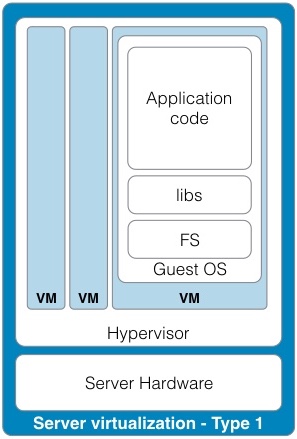 From an operations standpoint, Virtual Machines offer huge benefits: better capacity utilization, easier server provisioning, application isolation, and a familiar support interface because a virtual server looks like a physical server to operations. If the applications are written for it, and the hypervisor management systems support it, provisioning of a new virtual server can be done in a matter of minutes. For a developer, this is a huge benefit. Developers gain the ability to provision a server, deploy their code, and then test in a matter of hours. If there is a great deal of consistency between the development, staging, and testing environments, as well as extensive automation, this can be cut down to minutes. The same goes for environments that can be dynamically scaled. Properly configured VM Images can be brought on line to meet additional demand in minutes. This is the way Amazon Web Services Elastic Beanstalk works. However, there is room for dramatic improvement. Docker The UNIX based operating systems have offered the ability to isolate system processes for years. What if you created isolated system processes capable of running a Guest Operating System, like a VM but without all the overhead of a Hypervisor? What if rather than having dedicated and isolated system libraries, you could share dependencies and make the system images much smaller. Finally, what if you could completely isolate system dependencies in such a way that a container could run on any system? 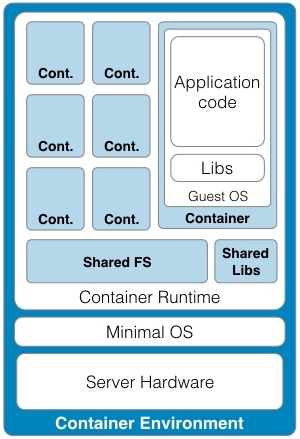 If you accomplished all of these things, you would have Docker. Docker is a system that exposes Linux containers in an incredibly easy to use way. A Docker based development workflow looks like this: 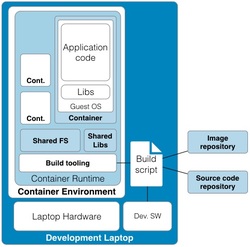 1. The developer downloads a container image from the image repository. 2. The developer writes their application code and commits it to the source code repository. 3. The developer writes a container *build script* to combine the source image, which is typically a very small bare bones Linux image, with the application code from the source code repository and any system libraries required by the application. 4. Once this build script is run, a completely self-contained container is created. This can now be uploaded into the Image Repository for promotion to any other Docker server or used as the basis for other applications. 5. If the application is to be composed of multiple applications, then another *composition script* can be written to define how application components are to be grouped together. This can even include resource utilization, scaling, networking, and host placement rules. The developers manage both the build and composition scripts in the same source code control application as the application code, therefore, making it easy for them to manage the entire application life cycle. 6. When it comes time to deploy the application code, all that is required is for the build and composition scripts to be executed and for the build pipeline to deploy the containers to the appropriate servers. It is at this point that the magic of containers comes into play. Rather than take minutes to deploy on a host server, containers take seconds or less. [25] As a result, it is now very feasible to enable fined grained elastic scaling for every application. Containers are so small and completely self contained, it is possible to create an application container on a developer laptop and run that exact same container in staging and production with no configuration changes. As a result, the Continuous Deployment process is greatly simplified because you no longer need to accomodate for different server configurations. This is a miracle for production support because even slight differences in deployment environments can be a nightmare to troubleshoot. Not to mention, you now have the ability to easily roll out or roll back different versions of an application in seconds. 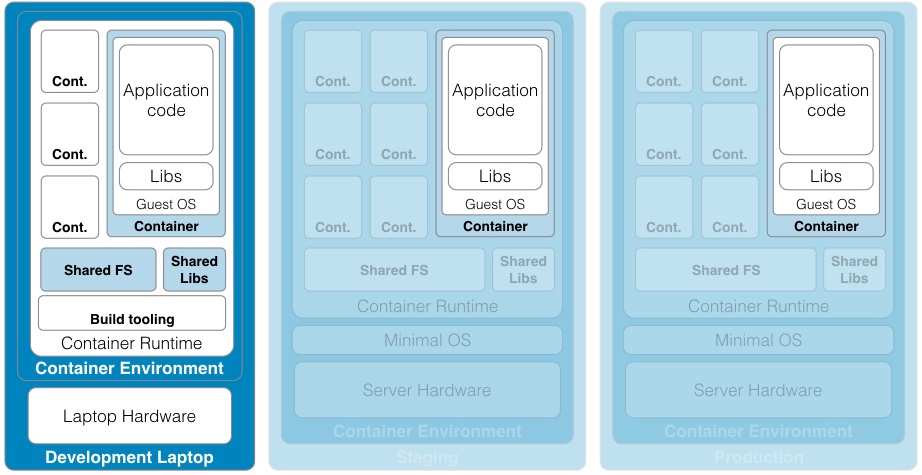 This deployment flexibility even extends to running containers in multiple container engines simultaneously. You could have containers at Amazon, Google, RackSpace, and a local ISP all running seamlessly! This a Hybrid Cloud that actually works. Of all of the technologies outlined above containers are the youngest. The 1.0 version of Docker was released in June 2014 and there have been constant improvements every month. It's young technology but this is how all applications will be managed and deployed in the future. As for production readiness of Linux containers, here is what Google has to say: Everything at Google, from Search to Gmail, is packaged and run in a Linux container. Each week we launch more than 2 billion container instances across our global data centers. [26] Summary Fortunately, all of these technologies are openly shared and are being aggressively implemented in companies of all sizes. One of the key reasons for this is the default adoption of Open Source software licensing and large scale adoption of code collaboration sites like GitHub and NPM. This significantly lowers the barrier to entry and provides a way for developers in multiple companies to collaborate transparently for the benefit of everyone who participates. Transparent participation is the cornerstone of this new way of doing business and an example of how you can take the seemingly gross disadvantage of perfect competition and turn it into an advantage. Companies who were founded on the idea that patents would protect you from competition have now discovered that patenting ideas actually decreases the rate of innovation. We find evidence that software patents substitute for R&D at the firm level; they are associated with lower R&D intensity. [27] Increasing the rate of innovation at the lowest possible cost is a major component of the first two values previously discussed. In fact, five of the ten innovations above would have been impossible without this level of openness. The other half fall under the category of shared or common practices designed to increase agility and collaboration. They all work together to provide a significant advantage to those who have adopted them. [28] Missing pieces There are three noticeable absences from this list because they don't come into play until you have established a significant customer base, which is a result of creating a wildly successful and ambitious product. Collectively, these are referred to as Big Data and individually they are Hadoop, stream processing, and machine learning. The reason they are not included is that, for a young, small company, they violate the Fiscal Responsibility value. They all require a significant initial capital investment as well as specialized skills. However, if you are a large, well established company with a significant volume of data to exploit, adopting these technologies can reduce licensing costs, improve the availability of the data, and provide new insights. Different problems require different solutions. [1] Best books on Lean Start-up:
Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers (http://www.amazon.com/Business-Model-Generation-Visionaries-Challengers-ebook/dp/B00BD6RFFS/ref=sr_1_1?s=books&ie=UTF8&qid=1443573162&sr=1-1&keywords=business+model+canvas) The Startup Owner's Manual: The Step-by-Step Guide for Building a Great Company (http://www.amazon.com/Startup-Owners-Manual-Step-Step-ebook/dp/B009UMTMKS/ref=pd_sim_351_2?ie=UTF8&refRID=1MEA67NDFVD8MYJTJKH4&dpID=51ZWp2QGZvL&dpSrc=sims&preST=_AC_UL160_SR124%2C160_) The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses (http://www.amazon.com/The-Lean-Startup-Entrepreneurs-Continuous-ebook/dp/B004J4XGN6/ref=pd_sim_351_3?ie=UTF8&refRID=1691QV9XANAQ3QNNB2ND&dpID=51gn6AuFkNL&dpSrc=sims&preST=_AC_UL160_SR106%2C160_) [2] It is hard to underestimate the impact the role that "Maker" focused companies like: Arduino, Fritzing, Makerbot, Kickstarter, and Easy have had on the rate of innovation in the hardware space. [3] It's hard to believe that one of the first uses of the term Service Oriented Architecture dates back to 1996 in a Gartner white paper "Service Oriented" Architectures, Part 1 (https://www.gartner.com/doc/302868?ref=ddisp) See: Service-Oriented Architecture Scenario (https://www.gartner.com/doc/391595/serviceoriented-architecture-scenario) for a non pay-wall overview. [4] The seminal book on this subject is: Domain-Driven Design: Tackling Complexity in the Heart of Software (http://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software-ebook/dp/B00794TAUG/ref=mt_kindle?_encoding=UTF8&me=) [5] Microservices (http://martinfowler.com/articles/microservices.html) [6] Conway's Law (http://www.melconway.com/Home/Conways_Law.html) [7] Inside the Mind of Jeff Bezos | Fast Company (http://www.fastcompany.com/50106/inside-mind-jeff-bezos) Jeff Bezos' 2 Pizza Rule: Why Small Teams Work More Productively (https://blog.bufferapp.com/small-teams-why-startups-often-win-against-google-and-facebook-the-science-behind-why-smaller-teams-get-more-done) [8] One of the Open Source tenets is that healthy discussion, debate, and competition are to be encouraged. In the short run, this may lead to duplicate effort but in the long run, a better system will evolve out of the struggle to best address the customer's needs. [9] This is well worth the read, both as a history and as guidance. In fact, if you only read one paper, this interview with Amazon CTO Werner Vogels is the one to read. A Conversation with Werner Vogels - ACM Queue (http://queue.acm.org/detail.cfm?id=1142065) [10] Building Microservices provides a thorough overview of micro services and the secondary infrastructure needed to support them in production. (http://www.amazon.com/Building-Microservices-Sam-Newman-ebook/dp/B00T3N7XB4/ref=mt_kindle?_encoding=UTF8&me=) [11] Challenges in Implementing MicroServices by Fred George (https://www.youtube.com/watch?v=yPf5MfOZPY0) [12] Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation is the foundational book on the DevOps process. (http://www.amazon.com/Continuous-Delivery-Deployment-Automation-Addison-Wesley-ebook/dp/B003YMNVC0/ref=pd_sim_351_3?ie=UTF8&refRID=02BEQJ5WCAG9E7DXDPWX&dpID=51yF2SYUi7L&dpSrc=sims&preST=_AC_UL160_SR121%2C160_) [13] Hapi Thanksgiving; It is about systems of nodes scaling, not node scaling (https://medium.com/ben-and-dion/hapi-thanksgiving-it-is-about-systems-of-nodes-scaling-not-node-scaling-5d96d900d904) [14] Proxying Services With Hapi.js (http://tech.opentable.co.uk/blog/2014/11/28/proxying-with-hapi/) Dismantling the monolith - Microsites at Opentable - OpenTable Tech UK Blog (http://tech.opentable.co.uk/blog/2015/02/09/dismantling-the-monolith-microsites-at-opentable/) Caching (http://hapijs.com/tutorials/caching) [15] Reactive Design should not to be confused with Responsive web design which try to provide a web interface optimized for the device being used. This web design technique leverages CSS and Javascript to allow one code base to be seamlessly usable across multiple browsers and devices. This greatly simplifies the codebase and can even eliminate the need for the creation of dedicated applications for phones and tablets. [16] While this may be debatable, in the context of Full Stack development, applications should only support JSON. If a conversion is required do this through a separate gateway function (e.g., XML to JSON converter). [17] To be honest, the same can be said for relational databases supporting ANSI SQL. Unfortunately, both relational and document database vendors offer their own variants of the "standard" query language. Hopefully, the noSQL vendors will settle on their own equivalent to ANSI SQL for querying JSON. [18] Take performance benchmarks with a grain of salt, but I happen to like this one because of its openness and reflection of real world use cases. Benchmark: PostgreSQL, MongoDB, Neo4j, OrientDB and ArangoDB (https://www.arangodb.com/2015/10/benchmark-postgresql-mongodb-arangodb/#more-8721) [19] noSQL 2009 (http://blog.sym-link.com/2009/05/12/noSQL_2009.html) [20] How Facebook flipped the data centre hardware market (http://www.theregister.co.uk/2014/02/20/facebook_hardware_feature/) [21] Open Compute Project Server and Storage Solutions - Penguin Computing (http://www.penguincomputing.com/products/open-compute-project/) [22] Amazon t2.micro - $.013 / hr. ($ 113.88 / yr.) (https://aws.amazon.com/ec2/pricing/) Google f1-small - .021 / hr. ($ 183.96 / yr.) (https://cloud.google.com/compute/#pricing) Microsoft A0 - $.018 / hr. ($ 157.68 / yr.) (https://azure.microsoft.com/en-us/pricing/details/virtual-machines/#Linux). Also look at the UnixBench table in [23] and notice the performance of the Raspberry Pi against the AWS t1.micro and m1.small. [23] Hypriot - Demo and challenge at DockerCon 2015 (http://blog.hypriot.com/post/dockercon2015/) [24] Intel Atom c2750 – 8 core Avoton / Rangeley benchmarks – fast and low power (http://www.servethehome.com/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/). If you look at the charts, it is interesting to note that The Intel C2750 servers outperform all of the AWS servers. Perhaps it is time to seriously reconsider co-location. The Intel Xenon D Review: Performance Per Watt Server SoC Champion?(http://www.anandtech.com/show/9185/intel-xeon-d-review-performance-per-watt-server-soc-champion) [25] Depending on the image size, a container can be spun up and removed in milliseconds. In fact, for certain workloads, it is actually preferable to spin up a container, run a process, and kill the container each time it is run rather than keep a container running. See: AWS Lambda (https://aws.amazon.com/lambda/) [26] Google Container Engine is Generally Available (http://googlecloudplatform.blogspot.com/2015/08/Google-Container-Engine-is-Generally-Available.html) [27] AN EMPIRICAL LOOK AT SOFTWARE PATENTS (http://www.researchoninnovation.org/swpat.pdf) [28] In particular, refer to the previous chart showing the stock price of Netflix. They have been at the forefront of aggressively adopting these technologies and the results speak for themselves; both for investors and consumers. Here's Why Consumers Love Netflix More Than Amazon and Hulu (http://www.adweek.com/news/television/here-s-why-consumers-love-netflix-more-amazon-and-hulu-165547) The Netflix Tech Blog (http://techblog.netflix.com) Wufoo exited with $35M on a $118K finding with 10 employees! SurveyMonkey to buy Wufoo (http://allthingsd.com/20110425/surveymonkey-buys-online-forms-start-up-wufoo-for-35-million/) Hacker News discussion (https://news.ycombinator.com/item?id=2481576) How to build products users love] (http://startupclass.samaltman.com/courses/lec07/)
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |

Brian McMillanSweating the details and still looking at the big picture. Archives
March 2022
Categories
All
|
 RSS Feed
RSS Feed